Data Extraction 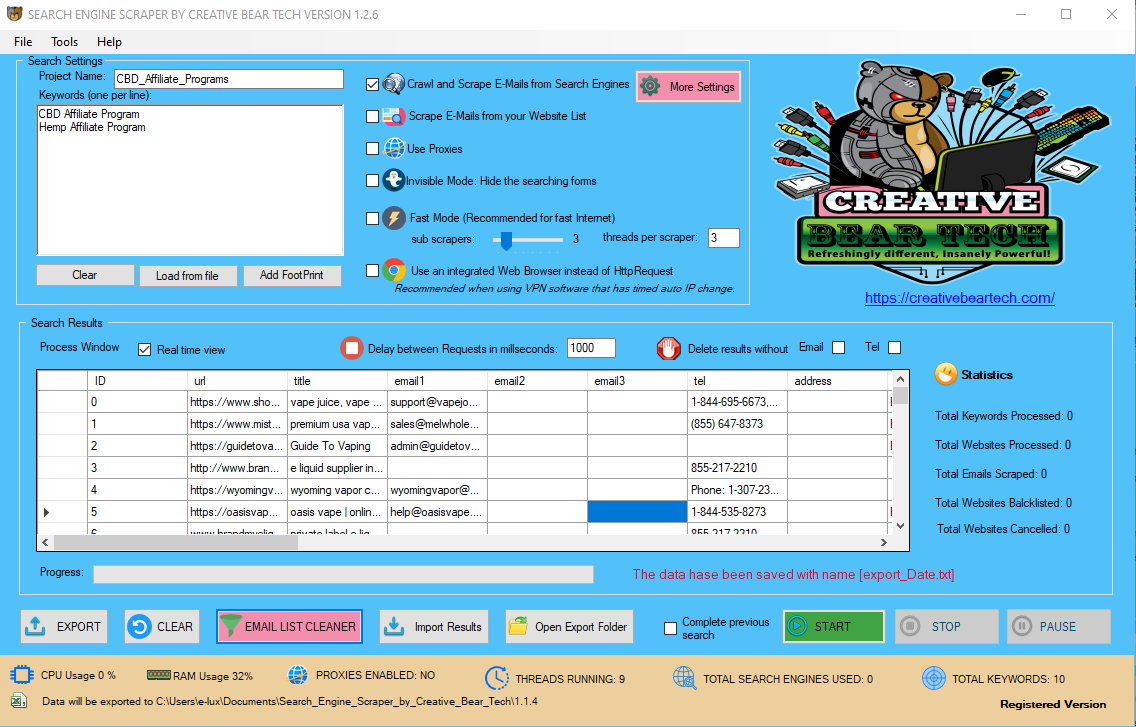
Data Extraction
This device permits you to arrange crawlers and fetch web knowledge in actual-time and likewise lets you save the gathered data immediately within the Google Drive or export it via CSV or JSON. One distinctive function of this tool is that the data may be extracted anonymously utilizing totally different proxy servers. This is an open source code growth framework which performs knowledge extraction with Python. This device allows builders to program crawlers to extract and observe data for one or many web sites without delay.
Data Sources
The requests sent using our information extraction tools won't get blocked and the information set shall be in your palms very quickly. Web scraping represents the process of extracting particular knowledge from an internet web page. Depending on the source, the output may be structured and thus - appropriate for analysis straight away.
Personal Tools
Once we've transformed your unstructured data into structured data there are limitless choices for additional processing. Aside from the benefits of improved compliance, visibility, and accuracy, information extraction has many distinctive use cases. Every industry can profit from the elevated productiveness and automation this service provides. Outsource2india is a number one outsourcing firm providing fast and efficient knowledge extraction services to world shoppers for over 21 years. We perceive that data extraction is extremely essential for any enterprise and guarantee highest possible accuracy of your extracted knowledge at highly inexpensive rates.
Tools
The streaming of the extracted knowledge source and load on-the-fly to the vacation spot database is one other method of performing ETL when no intermediate data storage is required. In basic, the aim of the extraction part is to convert the info right into a single format which is acceptable for transformation processing. By automating data entry processes for repetitive tasks, knowledge extraction instruments may help improve the accuracy of your knowledge inputs by reducing human errors. Data extraction consists of more than just scraping valuable enterprise information and compiling it in a spreadsheet for future use. Data extraction can also be used to perform exploratory evaluation and to extract relevant info from the data. Whether you propose to carry out a meta-evaluation or not, you'll need to establish a regimented approach to extracting information. Researchers typically use a type or desk to capture the data they will then summarize or analyze. The quantity and forms of knowledge you gather, in addition to the variety of collaborators who will be extracting it, will dictate which extraction instruments are greatest on your project.
Data Extraction Defined
The logic for incremental extraction is more complex, but the system load is reduced. We assist federal businesses, schooling institutions, healthcare organizations, and industrial businesses to embrace cloud based mostly automation instruments and progressive new processes. We save you money and time by compiling industry-main tools and pairing them with the experience and labor required to build and deploy them. Nowadays there are numerous tools or processes through which a developer can extract data from complex codecs similar to PDF or a number of web sites, which is named web scraping. Note that the intermediate system is not necessarily physically different from the source system. Many information warehouses do not use any change-capture techniques as a part of the extraction process. This method may not have important impact on the source systems, but it clearly can place a considerable burden on the information warehouse processes, particularly if the information volumes are large. We can present begin to finish solutions to extract, index, and deploy your data. In order to entry and distribute this data, there are a lot of tools or processes by way of the use of programming languages. Sometimes that information is structured and on other occasions it is unstructured. Data extraction tools automated the process of web harvesting at many levels. They are clever sufficient to inspect the net buildings, parse the HTML, fetch the data, and combine into your database multi functional suite.
JustCBD CBD Gummies - CBD Gummy Bears https://t.co/9pcBX0WXfo @JustCbd pic.twitter.com/7jPEiCqlXz
— Creative Bear Tech (@CreativeBearTec) April 27, 2020
This event could be the final time of extraction or a extra complicated enterprise occasion like the last reserving day of a fiscal period. To determine this delta change there must be a chance to determine all the modified information since this particular time occasion. Raw knowledge is data collected from a source, which has not yet been processed for utilization.Typically, the available data isn't in a state by which it can be used effectively for knowledge extraction. Such information is troublesome to manipulate and often needs to be processed ultimately, before it may be used for information analysis and knowledge extraction normally, and is known as raw knowledge or source data. This article lists a number of the most popular knowledge extraction tools and the way these tools can be utilized for business benefits. Depending on how much information you require, web pages might want to get crawled and scraped repeatedly hundreds or 1000's of occasions. We will use proxies and rotate IP addresses, time-out requests and provide you with asynchronous computing options so that you just would not have to. Even worse, folks may unsubscribe your e-mail or mark you as spam. In order to gather quality prospects from websites, we need to optimize the search course of. Capture your unstructured information in actual time and promote informed decision-making and collaboration through massive information. Decision makers want insightful knowledge to take key business selections. 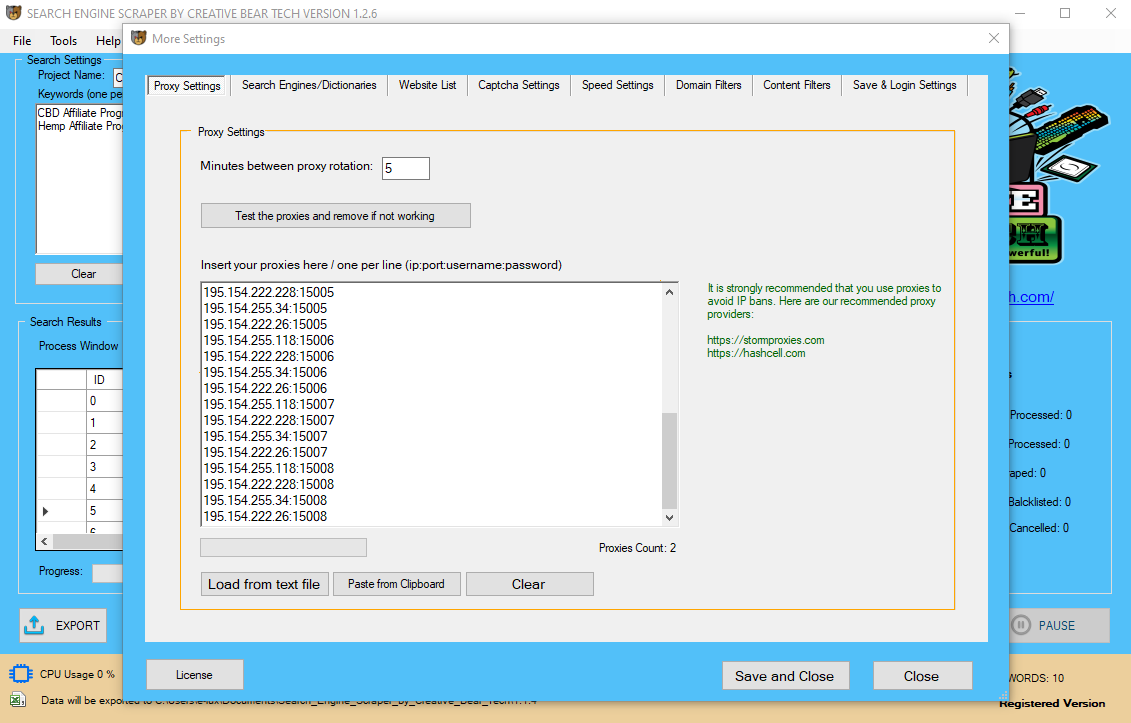 With FindDataLab you possibly can harvest information from a number of totally different web sites or a number of pages of 1 net web page. Our data extraction tools will crawl the online and extract the data that you need. We can scrape one website Twitter Scraper and Data Extractor or mix the information extracted from a number of sources. After that, we are going to apply the appropriate data wrangling options to clean up your data and provide you with an evaluation-prepared knowledge set. This growing course of of information extraction from the web is known as "Web data extraction" or "Web scraping". Data extraction is the act or means of retrieving knowledge out of (normally unstructured or poorly structured) knowledge sources for further data processing or knowledge storage (information migration). The import into the intermediate extracting system is thus often followed by data transformation and probably the addition of metadata previous to export to another stage in the information workflow. Data analysis can open up a bunch of new alternatives for your business. Since this extraction displays all the data presently obtainable on the source system, there’s no must hold monitor of changes to the data supply for the reason that last successful extraction. The supply knowledge might be offered as-is and no additional logical info (for example, timestamps) is necessary on the source site. An instance for a full extraction may be an export file of a definite desk or a distant SQL statement scanning the complete source table. These are necessary considerations for extraction and ETL generally. For instance, you would possibly wish to carry out calculations on the data — such as aggregating sales knowledge — and store those leads to the info warehouse. If you are extracting the info to store it in an information warehouse, you may wish to add further metadata or enrich the information with timestamps or geolocation information. Finally, you probably need to mix the information with different data within the goal information retailer. These processes, collectively, are called ETL, or Extraction, Transformation, and Loading. Typical unstructured data sources embrace web pages, emails, paperwork, PDFs, scanned textual content, mainframe stories, spool recordsdata, classifieds, and so on. which is additional used for sales or advertising leads. It can also rework your corporation by preserving you from spending too much time on duties like manual information entry. You can merely automate it all with a set-it-and-overlook-it knowledge scraping course of. Data extraction is a course of that includes retrieval of knowledge from numerous sources. Frequently, companies extract data in order to course of it additional, migrate the data to a knowledge repository (such as a data warehouse or a knowledge lake) or to further analyze it.
With FindDataLab you possibly can harvest information from a number of totally different web sites or a number of pages of 1 net web page. Our data extraction tools will crawl the online and extract the data that you need. We can scrape one website Twitter Scraper and Data Extractor or mix the information extracted from a number of sources. After that, we are going to apply the appropriate data wrangling options to clean up your data and provide you with an evaluation-prepared knowledge set. This growing course of of information extraction from the web is known as "Web data extraction" or "Web scraping". Data extraction is the act or means of retrieving knowledge out of (normally unstructured or poorly structured) knowledge sources for further data processing or knowledge storage (information migration). The import into the intermediate extracting system is thus often followed by data transformation and probably the addition of metadata previous to export to another stage in the information workflow. Data analysis can open up a bunch of new alternatives for your business. Since this extraction displays all the data presently obtainable on the source system, there’s no must hold monitor of changes to the data supply for the reason that last successful extraction. The supply knowledge might be offered as-is and no additional logical info (for example, timestamps) is necessary on the source site. An instance for a full extraction may be an export file of a definite desk or a distant SQL statement scanning the complete source table. These are necessary considerations for extraction and ETL generally. For instance, you would possibly wish to carry out calculations on the data — such as aggregating sales knowledge — and store those leads to the info warehouse. If you are extracting the info to store it in an information warehouse, you may wish to add further metadata or enrich the information with timestamps or geolocation information. Finally, you probably need to mix the information with different data within the goal information retailer. These processes, collectively, are called ETL, or Extraction, Transformation, and Loading. Typical unstructured data sources embrace web pages, emails, paperwork, PDFs, scanned textual content, mainframe stories, spool recordsdata, classifieds, and so on. which is additional used for sales or advertising leads. It can also rework your corporation by preserving you from spending too much time on duties like manual information entry. You can merely automate it all with a set-it-and-overlook-it knowledge scraping course of. Data extraction is a course of that includes retrieval of knowledge from numerous sources. Frequently, companies extract data in order to course of it additional, migrate the data to a knowledge repository (such as a data warehouse or a knowledge lake) or to further analyze it.
- After that, we are going to apply the appropriate data wrangling solutions to wash up your data and offer you an analysis-prepared knowledge set.
- With FindDataLab you can harvest knowledge from multiple different websites or multiple pages of one net web page.
- Our data extraction instruments will crawl the net and extract the information that you just want.
- We can scrape one website or mix the info extracted from multiple sources.
When combined with our business process outsourcing, the result's high influence with minimal disruption. Data extraction is a key element in a fully realized information management technique. DOMA makes use of the newest information extraction instruments to enhance business intelligence. 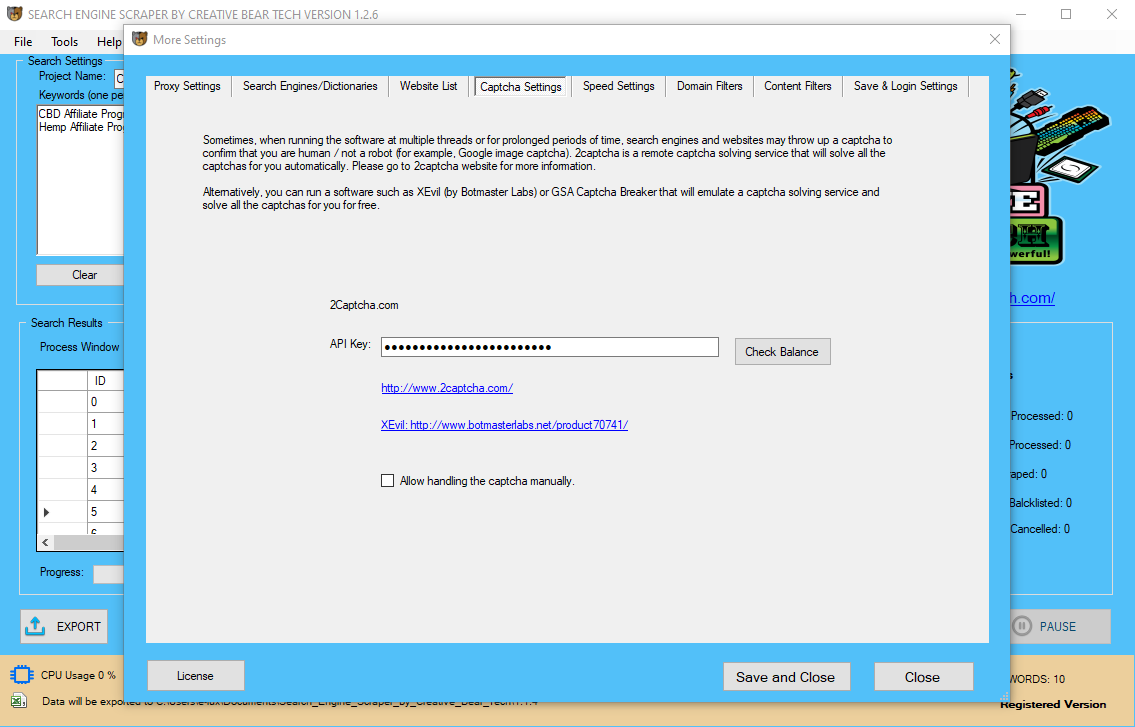 In this article, I want to introduce 9 extremely cost-efficient knowledge extraction instruments which are constructed for non-coders. is a community-driven, searchable, net-primarily based catalogue of tools that assist the systematic evaluate course of throughout multiple domains. Use the advanced search option to restrict to tools particular to data extraction. However, when dealing with cumbersome information and fewer manpower, companies often wrestle to attract priceless inferences. Leveraging rigorously chosen data extraction instruments can help corporations well timed analyze information and avail its advantages. Most knowledge warehousing projects consolidate knowledge from completely different supply techniques. Each separate system may also use a special information organization/format. Data extraction doesn't essentially mean that entire database structures are unloaded in flat recordsdata. In many cases, it may be appropriate to unload entire database tables or objects. In other instances, it might be extra acceptable to unload solely a subset of a given table such as the adjustments on the supply system since the last extraction or the outcomes of joining a number of tables collectively. Different extraction techniques vary in their capabilities to support these two situations. Unfortunately, for many source systems, identifying the recently modified knowledge could also be troublesome or intrusive to the operation of the system. Change Data Capture is often the most difficult technical issue in knowledge extraction. The data isn't extracted directly from the source system however is staged explicitly exterior the unique supply system. The information already has an existing construction (for example, redo logs, archive logs or transportable tablespaces) or was created by an extraction routine. It routinely searches and extracts tens of millions of leads in a short while. Now, there are lots of decisions available on the market, which one you must depend on? Your decision ought to be based mostly on the evaluation of your staff’s distinctive wants. I would advocate taking one-two weeks of POC(Proof of Concept) and testing out whether it can get you desired data. Any software that may improve processes and save time must be explored. When used appropriately, knowledge extraction tools can save your small business time, giving staff time to focus on more necessary duties. They are all ready-to-use knowledge extraction tools to drag information from popular websites. If anybody is talking about knowledge extraction tools, he/she will inevitably point out Octoparse. As a robust tool with many advanced options, it stands out as one of the best in the knowledge extraction software program industry. Some of them work great for programmers whereas some go well with non-coders well. The data has to be extracted normally not only once, however several times in a periodic method to supply all modified data to the warehouse and stick with it-to-date. Moreover, the supply system sometimes cannot be modified, nor can its performance or availability be adjusted, to accommodate the wants of the info warehouse extraction process. However, the perceived web knowledge takes many varieties, from textual content and URLs to images and videos.
In this article, I want to introduce 9 extremely cost-efficient knowledge extraction instruments which are constructed for non-coders. is a community-driven, searchable, net-primarily based catalogue of tools that assist the systematic evaluate course of throughout multiple domains. Use the advanced search option to restrict to tools particular to data extraction. However, when dealing with cumbersome information and fewer manpower, companies often wrestle to attract priceless inferences. Leveraging rigorously chosen data extraction instruments can help corporations well timed analyze information and avail its advantages. Most knowledge warehousing projects consolidate knowledge from completely different supply techniques. Each separate system may also use a special information organization/format. Data extraction doesn't essentially mean that entire database structures are unloaded in flat recordsdata. In many cases, it may be appropriate to unload entire database tables or objects. In other instances, it might be extra acceptable to unload solely a subset of a given table such as the adjustments on the supply system since the last extraction or the outcomes of joining a number of tables collectively. Different extraction techniques vary in their capabilities to support these two situations. Unfortunately, for many source systems, identifying the recently modified knowledge could also be troublesome or intrusive to the operation of the system. Change Data Capture is often the most difficult technical issue in knowledge extraction. The data isn't extracted directly from the source system however is staged explicitly exterior the unique supply system. The information already has an existing construction (for example, redo logs, archive logs or transportable tablespaces) or was created by an extraction routine. It routinely searches and extracts tens of millions of leads in a short while. Now, there are lots of decisions available on the market, which one you must depend on? Your decision ought to be based mostly on the evaluation of your staff’s distinctive wants. I would advocate taking one-two weeks of POC(Proof of Concept) and testing out whether it can get you desired data. Any software that may improve processes and save time must be explored. When used appropriately, knowledge extraction tools can save your small business time, giving staff time to focus on more necessary duties. They are all ready-to-use knowledge extraction tools to drag information from popular websites. If anybody is talking about knowledge extraction tools, he/she will inevitably point out Octoparse. As a robust tool with many advanced options, it stands out as one of the best in the knowledge extraction software program industry. Some of them work great for programmers whereas some go well with non-coders well. The data has to be extracted normally not only once, however several times in a periodic method to supply all modified data to the warehouse and stick with it-to-date. Moreover, the supply system sometimes cannot be modified, nor can its performance or availability be adjusted, to accommodate the wants of the info warehouse extraction process. However, the perceived web knowledge takes many varieties, from textual content and URLs to images and videos.
Beauty Products & Cosmetics Shops Email List and B2B Marketing Listhttps://t.co/EvfYHo4yj2
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Beauty Industry Marketing List currently contains in excess of 300,000 business records. pic.twitter.com/X8F4RJOt4M
The process of information extraction entails retrieval of knowledge from disheveled knowledge sources. The knowledge extracts are then loaded into the staging area of the relational database. Here extraction logic is used and supply system is queried for knowledge utilizing utility programming interfaces. Alooma's clever schema detection can handle any sort of input, structured or in any other case. Changes within the source data are tracked since the final profitable extraction in order that you do not undergo the process of extracting all the info each time there is a change. To do this, you would possibly create a change desk to track adjustments, or check timestamps. Some knowledge warehouses have change information seize (CDC) performance built in. Following this course of, the data is now ready to go through the transformation section of the ETL course of. The majority of data extraction comes from unstructured knowledge sources and different knowledge formats. This unstructured knowledge may be in any type, corresponding to tables, indexes, and analytics. Tabula scrapes the data within the table and offers the person with a preview of the knowledge extracted for it to be checked. This internet scraping device would not want any sort of download and is a browser-based mostly software.
Global Hemp Industry Database and CBD Shops B2B Business Data List with Emails https://t.co/nqcFYYyoWl pic.twitter.com/APybGxN9QC
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
What makes DOMA completely different is that we offer more than a single focused software. We integrate multiple kinds Is web scraping legal? of knowledge extraction tools to create holistic solutions that can handle larger challenges inside your business.
Global Vape And CBD Industry B2B Email List of Vape and CBD Retailers, Wholesalers and Manufacturershttps://t.co/VUkVWeAldX
— Creative Bear Tech (@CreativeBearTec) June 16, 2020
Our Vape Shop Email List is the secret sauce behind the success of over 500 e-liquid companies and is ideal for email and newsletter marketing. pic.twitter.com/TUCbauGq6c
This tool has an extension for Mozilla Firefox and Chrome which makes it easy to entry and is mainly used to extract hyperlinks, email ids, data tables, images, and so on. If you're unable to finish your request utilizing our self-service tools or have a more advanced data pull, you'll be able to submit a Data Extraction request by way of our CTSI Service Request Form. Initial consultation on information wants and information requests for simple queries and/or data pulls are available for free of charge. The three cornerstones of information extraction - net crawling, net scraping, and data wrangling are all incorporated into FindDataLab's internet scraping toolkit. Data extraction is the spine of a modern enterprise intelligence toolkit. This chapter, nevertheless, focuses on the technical issues of getting completely different sorts of sources and extraction methods. It assumes that the data warehouse team has already recognized the info that will be extracted, and discusses common strategies used for extracting knowledge from supply databases. Designing and creating the extraction process is commonly one of the time-consuming duties within the ETL course of and, certainly, in the whole information warehousing process. The supply techniques might be very complex and poorly documented, and thus figuring out which information must be extracted may be difficult. This is likely one of the hottest web scraping instruments available out there at present. It normally segregates the web pages into different components after which navigates from page to page to extract the related information from the website. More generally, however, the raw information is unstructured and needs to be prepared for evaluation. FindDataLab's data extraction tools will handle JavaScript and dynamically loading web sites, in addition to use proxies and time-outs to extract knowledge in a timely and moral Mobile Proxies manner. We are the main agency by delivering quality and value to our clients. At a selected point in time, only the info that has changed since a properly-defined event back in history might be extracted. In most circumstances, using the latter methodology means adding extraction logic to the source system. Using information extraction to remain on high of information processing allows your staff to get their arms on data quicker. This easy strategy of extracting and storing data means it is more visible to everybody in your corporation that should see it. Data extraction is the process of getting information from a source for additional knowledge processing, storage or evaluation elsewhere. Data extraction is the place knowledge is analyzed and crawled via to retrieve related data from knowledge sources (like a database) in a specific pattern. Further information processing is completed, which involves adding metadata and different information integration; another course of in the knowledge workflow. Alooma can work with nearly any supply, each structured and unstructured, and simplify the method of extraction. Alooma allows you to perform transformations on the fly and even mechanically detect schemas, so you possibly can spend your time and power on evaluation. For example, Alooma supports pulling data from RDBMS and NoSQL sources. And they're only accessible when we browse the internet or copy-paste the data into a local drive. This would take up your time on amassing useful information in time and organizing into a possible format. Because of this, you don’t have to keep doing mundane work time and again. Instead, web data extraction offers you with the ability to acquire net information from multiple sources at one time. 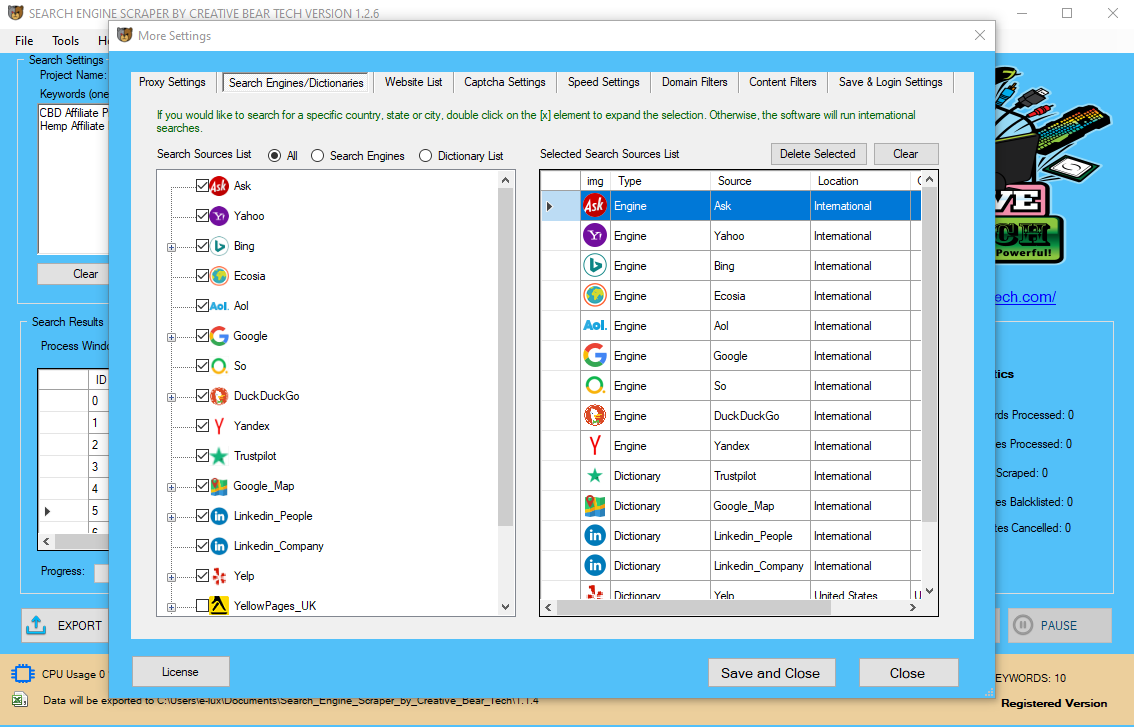 The time period information assortment is commonly used when speaking about data extraction. Needless to say, it's so important for a business to get profitable — extra leads! Of course, you should buy contact lists, however they are not quality leads.
The time period information assortment is commonly used when speaking about data extraction. Needless to say, it's so important for a business to get profitable — extra leads! Of course, you should buy contact lists, however they are not quality leads.
Food And Beverage Industry Email Listhttps://t.co/8wDcegilTq pic.twitter.com/19oewJtXrn
— Creative Bear Tech (@CreativeBearTec) June 16, 2020